新しい WordPress の Plugin を作っています。
 マルチバイト文字の パーマリンク や Slug は、その地方の人には目に止まりやすいのかも知れませんが、 エンコードされて エンティティ化されてしまうと美しくありません。
マルチバイト文字の パーマリンク や Slug は、その地方の人には目に止まりやすいのかも知れませんが、 エンコードされて エンティティ化されてしまうと美しくありません。
更に、 WordPress では文字数制限という悩みどころも有り、バイト文字で表現できる英文表記にしたいところです。
2014.03.07 更新分
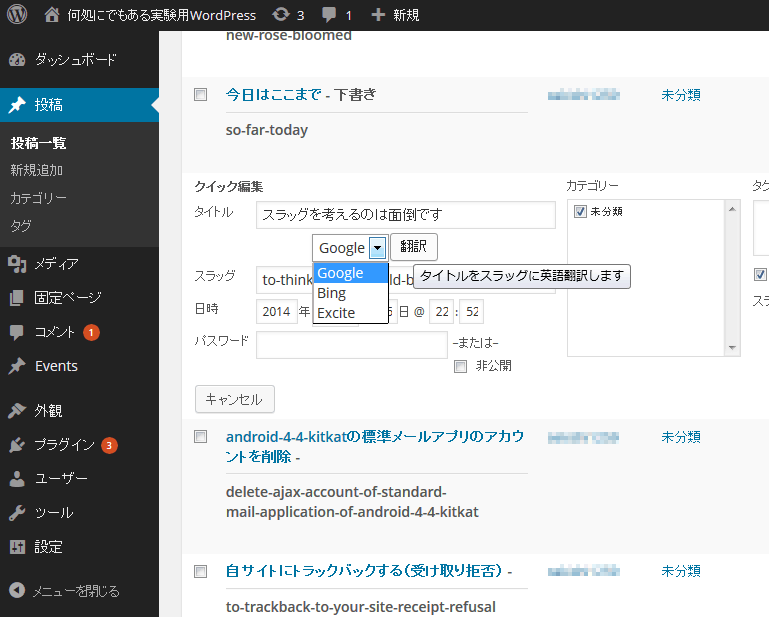
現在ローカルのWordPressでの実装状況
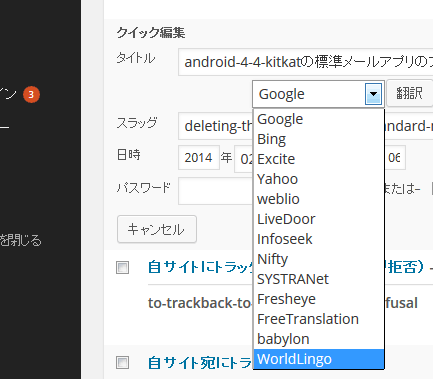
Slug ごときにこんなに翻訳エンジンが必要かというジレンマ、 この数ではリリースしても保守しきれないという問題が浮上。 Slug は Google Bing WorldLingo あたりに限定してリリースして、翻訳まとめサイトでも作ったほうが利口な気がします。
そして 2014.03.12 こうなる…。翻訳サイトって、リンクリンクの数珠つなぎで辿っていくと、基本エンジンにたどり着くわけだけれど、結構数がある。

制作動機は物ぐさ
記事を書くとタイトルで悩んだりする事がある訳ですが、そのタイトルから更に英文を考えるのは面倒だと感じる訳で、現在 WordPress の Slug をタイトルから 自動翻訳 し、投稿一覧でクイック編集からも再設定できる Plugin を制作中です。
そもそも畑違いで、 スクレイピング という単語を始めて知ったり、 JSON 、 ajax は言葉と意味は知っていたものの、実作業上で扱うのは初めてという有様なので、温かく見守っていただければ幸いです。
因みに ajax というと、筆者的にはこれなのですが…、

異論があればコメントで受け付けます。
そんな訳で、現在は 翻訳API の動作や スクレイピング の手法の勉強もかねて、ローカルマシン上の WordPress で実験中です。
形としては既に出来上がっているのですが、翻訳取得部分がやや未熟です。
許容できるレベルになり次第、 WordPress のオフィシャルディレクトリへ登録するので今しばらくお待ちください。
作成途中の物を lab.planetleaf.com の WordPress に実装していますが、タイトルを書き終えた時点で英文Slugが出来上がっているので、字若干の修正をするだけで済みます。これはらくちん。
翻訳サービス
覚書としてリストアップしますが、全部が実装候補なわけではありません。転送量の問題もあり、 Mobile サイトをリクエスト出来ないサービスはその段階で排除しています。取得結果が2万文字以下というのが理想です。
数が多くなったので別ページへ移動しました。
オンライン 翻訳サービス のまとめ | Planetleaf.com Lab.
https://lab.planetleaf.com/network/summary-of-online-translation-service.html
スクレイピング
Google翻訳 は クエリー の結果を JSON 形式で受け取れるので苦労しないのですが、 Yahoo翻訳 や Excite翻訳 は クエリー の結果を Webページ として取得して分解しなければいけません。
Excite を例に PHP を使用して分解してみます。
最初に考えたのが以下のコードです。 User-Agent を指定して Moblie サイトを要求しています。
$url = 'http://www.excite.co.jp/world/english/?wb_lp=JAEN&before=' .urlencode($text);
$args = array(
'http'=>array(
'method' => 'GET',
'ignore_errors' => 'true',
'header' =>
"Referer: http://www.excite.co.jp/world/english/\r\n".
"User-Agent: Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_2 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5\r\n"
)
);
$context = stream_context_create($args);
$body = file_get_contents($url, false, $context);
$response = strpos($http_response_header[0], '200');
if ( $response ) {
if( preg_match('/<section id="after_sec">.*?<p>(.*?)<\/p>/s', $body, $matches) ){
$ret = str_replace(' ', '-', strtolower( $matches[1] ));
}
}
ただ、正規表現でざっくりという、いつ動かなくなるかも知れない日曜プログラム的な物は、安定を求める業務コードとしては失格らしく、最終的に以下のようなコードに落ち着きました。
$url = 'http://www.excite.co.jp/world/english/';
$content = array(
'wb_lp' => 'JAEN',
'before' => $text
);
$content = http_build_query( $content );
$header = array(
"Content-Type: application/x-www-form-urlencoded",
"Content-Length: ".strlen( $content ),
"Referer: http://www.excite.co.jp/world/english/",
"User-Agent: Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_2 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5"
);
$header = implode( "\r\n" , $header );
$args = array( 'http' => array(
'method' => 'POST',
'ignore_errors' => 'true',
'header' => $header,
'content' => $content
)
);
$context = stream_context_create($args);
$html = file_get_contents($url, false, $context);
$response = strpos($http_response_header[0], '200');
if ( $response ) {
$dom = new DOMDocument();
@$dom->loadHTML($html);
$transtext = $dom->getElementById('after_sec')->getElementsByTagName('p')->item(0)->textContent;
$ret = strtolower( $transtext );
$ret = preg_replace("/[ .]/","-", $ret );
$ret = preg_replace("[-+]","-", $ret );
}
一応調べ上げての結果ですが、筆者はWeb系の伝手が皆無なため、これが本当に正しく、美しい手法なのかという判断が付きません。
恐らく突っ込みどころ満載なのかと思いますが、気が付かれた点があればコメント頂ければと思います。